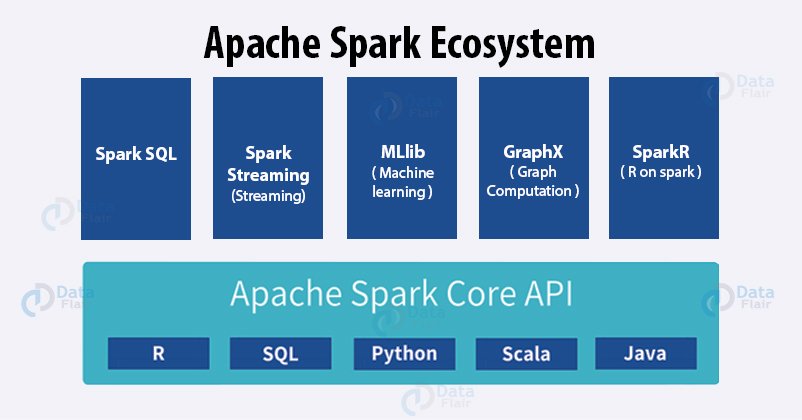
Spark Ecosystem
Apache Spark is trending, lightning fast big-data solution. It has appealing development API’s which allow data workers to accomplish streaming, machine learning, or SQL workload that requires continuous access to datasets. It can perform batch processing and stream processing. It is a generalized platform for cluster computing. The Spark Ecosystem depicts all the functionalities that Spark provides and also tells the features of Apache Spark. The Ecosystem consists of 6 main components:
- Spark Core
- Spark SQL
- Spark Streaming
- MLlib
- GraphX
- SparkR
1. Spark Core
The Foundation of Apache Spark Ecosystem is the Spark Core. All the functions that Apache spark provides are on the top of Spark Core. Spark core facilitates the computation by providing parallel and distributed processing of large dataset. There are various features that Spark core provides for that make Spark a promising framework for Bigdata solution. Some of the features of Apache Spark Core are it takes care of input-output functionalities, it helps to overcome the limitations of Hadoop MapReduce, also provides fault recovery and task dispatching.
The abstraction of Apache Spark i.e. RDD is embedded on Apache Spark Core. All the partitioning across the cluster is handled by RDD. The two main operation that RDD provide is Transformation and Action.
Transformation produces new RDD from the existing one. On the introduction of transformation operation always a new RDD is created. Upon action it does not create new RDD rather it computes the result and sends it to the driver program.
2. Spark SQL
For the purpose of structured data processing Spark makes use of SQL components. Just like RDD API, the Spark SQL provides information about the structure of the data and the computation that is being performed. It also allows executing SQL queries and reading from an existing HIVE installation. SQL returns the result as DataSet/DataFrame when running SQL within another programming language. It can access both the structured and semi-structured information. With Spark SQL as the Spark gets more information, it is capable of performing extra optimization. In Spark SQL there is no dependence on API/language to express computation. As a result, it is distributed SQL query engine.
In Spark SQL the optimization so performed is cost-based optimization. It is has a provision for fault-tolerance but it can handle only mild queries. It scales several nodes and multi-hour query with the help of Spark engine. We can commonly access a variety of Data sources with DataFrame and SQL. For example Hive, Avro, Parquet, ORC, JSON, and JDBC.
3. Spark Streaming
Spark streaming is built on the top of Spark Core. It provides high throughput, fault tolerant, stream processing of live data stream. The data in live streaming can be from any sources like Kafka, Flume, and Kinesis or TCP socket. This data is processed using various complex algorithms. These algorithms consist high-level functions like map, reduce, joinandwindow. Once the processing of data is complete the data is pushed to the file system, databases, and live dashboards. For the purpose of real-time streaming, it uses batch processing.
We can also apply graph processing and machine learning algorithms on this set of streaming data. Spark Streaming provides an abstraction known as the discretized stream or DStream. The Streaming program so written can be in Scala, Java or Python. For all the streaming functionality StreamingContext is the entry point.
It provides methods used to org.apache.spark.streaming.dstream.DStream from various input sources. Spark Streaming provides an abstraction known as the discretized stream or DStream.
4. MLlib
Through Machine Learning Spark provides a provision for high Speed and high-quality algorithm. Spark takes Machine learning to next level by making it easy and scalable. The libraries of machine learning contain various algorithms that have implementations of clustering, regression, classification and collaborative filtering.
In Spark Version 2.0 release the DataFrame-based API is the primary Machine Learning API for Spark.The DataFrame-based API is much better than RDD as it is more user-Friendly. Some of the benefits are it includes Spark Data sources, SQL DataFrame queriesTungsten and Catalyst optimizations, and uniform APIs across languages.
Some lower level machine learning primitives like generic gradient descent optimization algorithm are also available in MLlib.
5. GraphX
It is that component of Spark Ecosystem that supports Graph and Graph parallel computation. At its high-level Spark, graph extends the basic abstraction of Spark i.e. RDD to next level. It does this by introducing new graph abstraction i.e. a directed multigraph with properties attached to its every vertex and edge. To simplify the task of graph computation it has a collection of Graph algorithms and builders. The graph builder contains several ways of building a graph from a collection of vertex and edge in RDD or on disk.
6. Spark R
It is R package that allows using Apache Spark from R along with rich optimization. It is distributed DataFrame implementation that supports operations like Selection filtering, aggregation. It allows distributed Machine Learning through MLlib. SparkSession is the entry point to the Spark R that connects R to Spark cluster. To create SparkSession you can use sparkR.session and pass it to the application name. When working with Spark shell, SparkSession is already created and there is no need to call sparkR.session. We can also initiate SparkR from RStudio. To connect R program to Spark cluster use RStudio, RScript or other RIDE’s.